MPI4Py
MPI4Py je knjižnica za Python s katero lahko paralelno izvajamo Python programe na računskih sestavih. Zmogljivost MPI4Py je ob uporabi spremnih knjižnic numpy in scipy pri srednje do velikih matričnih problemih do 5% manjša kot če bi uporabljali Fortran ali C, kar daje spobudo, da lahko “novodobniki” preskočijo učenje teh jezikov. Pri vlaganju truda v razvoj še hitrejše kode pa vejla pravilo 90/10, ki pravi, da je se 90% računskega časa porabi v 10% kode. Se pravi, da je le malo aplikacij, ki bi jim koristila prevedena koda.
Dokumentacija za vaje iz MPI4Py je na voljo na http://mpi4py.scipy.org/ in http://numpy.scipy.org/
Poganjanje programov MPI4Py
- Prijavi se za komentar
Za poganjanje MPI programov je potrebno namestiti paralelno okolje OpenMPI in Python z ukazom
module load openmpi python
Knjižnica mpi4py je v lokalno nameščeni pyton tudi nameščena, kar preverimo z naslednjim programom. Osnovni testni program hello.py s poljubni urejevalnikom pripravimo za test
# -*- coding: utf-8 -*-
from mpi4py import MPI
comm = MPI.COMM_WORLD
print "Zdravo! Jaz sem proces %d od skupaj %d procesov" % (comm.rank, comm.size)
comm.Barrier() # Počakajmo vse, da pridejo do to, potem pa nadaljujemo
Po namestitvi poganjamo programe z ukazom
bsub -n 4 -o error.log mpirun python hello.py
Rezultat si preberemo v datoteki error.log ki, jo beremo na nadzornem vozlišču prelog. Za interaktivno delo na enem samem vozlišču ali pa na polovici vozlišča pa lahko uporabimo tudi ukaza
node mpirun python hello.py
half mpirun python hello.py
Hello world
Napiši program hello.py, ki izpiše klasičen pozdrav.
# -*- coding: utf-8 -*-
from mpi4py import MPI
comm = MPI.COMM_WORLD
print “Zdravo!”
comm.Barrier()
- Poženi program v
- Ospredju z ukazom node in half tako da je mpirun kot argument ali tako, da greste najprej na vozlišče in tam poženete ukaz. Podajte tudi manjše število procesorjev z ukazom bsub -n št.proc
- v ozadju z ukazom bsub in izbranim številom procesorjev ter izpisom izhoda v datoteko.
- V interaktivnem ozadju z ukazom bsub -k
- Uporabite naslednji funkciji za določitev številke procesa
size = comm.Get_size()
rank = comm.Get_rank()
in nato uporabite printf() za izpis.
- Popravite program, da se izpiše samo glavni proces (rank 0)
Uporabite stavek if. To je koristno, ko imamo veliko procesov.
- Kaj se zgodi če izpustimo zadnji stavek? MPI_Init() in MPI_Init_thread() se kličeta ob
import mpi4py. Prav tako je nastavljen MPI_Finalize() da se izvede kot ukaz Py_AtExit().
- Naredimo tri različne naloge, ki pa naj se hkrati izvedejo
# -*- coding: utf-8 -*- tris.py
from mpi4py import MPI
rank = MPI.COMM_WORLD.Get_rank()
a = 6.0
b = 3.0
if rank == 0:
print "Rezultat seštevanja:", a + b
if rank == 1:
print a * b
if rank == 2:
print max(a,b)
Paralelno računanje števila Pi (π)
Aproksimacija števila π se lahko dobi z naslednjim približkom
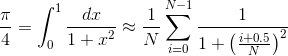
kjer se odgovor dobi s približkom, ki postaja boljši z naraščajočim N. Iteracije so med seboj neodvisne od i in s tem jih je tako možno paralelizirati. Za naslednje primere uporabite N=2310, ki je deljivo z 2,3,4,5,6,7,8,9,10,11 in 12
- Popravite hello.py tako, da bo vsak proces neodvisno izračunal vrednost π in ga izpisal na zaslon
# -*- coding: utf-8 -*- pi0.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
N = 2310
vsota=0.0
for i in range(N):
vsota += 1/(1+((i+0.5)/N)**2)
print "Pi = ", 4*vsota/N - Sedaj uporabite različne procese, da bodo po delih izračunali vsoto. Če imamo samo dva procesa, potem bo rank 0 izračunal i v mejah od i=0,1,N/2-1 ter rank 1 v mejah i=N/2..N-1. Program poženemo z ukazom
half mpirun -np 2 python pi1.py
Upoštevajte, da je
range([start,] stop[, step]) -> list of integersNa roke seštejte in preverite, če so delne vsote pravilne.
# -*- coding: utf-8 -*- pi1.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
N = 2310
vsota = 0.0
start = rank*N/size
stop = (rank+1)*N/size
for i in range(start, stop):
vsota += 1/(1+((i+0.5)/N)**2)
print "%f rank %d [%d,%d]" % (4*vsota/N, rank, start, stop)Za večje število procesov uporabimo awk
node mpirun -np 11 python pi1.py|awk '{sum+=$1}END{print "Pi=",sum}' - Sedaj želimo v glavnem procesu (rank 0) sešteti vse delne vsote tako da
- Vsi procesi razen glavnega pošljejo svojo delno vsoto glavnemu procesu
- Glavni proces sprejme v vrednosti vseh ostalih procesov in jih sešteje v zanki
# -*- coding: utf-8 -*- pi2.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
N = 2310
vsota = 0.0
start = rank*N/size
stop = (rank+1)*N/size
for i in range(start, stop):
vsota += 1/(1+((i+0.5)/N)**2)
if rank == 0:
for i in range(1, size):
vsota += comm.recv(source=i, tag=1)
print "Pi =", 4*vsota/N
else:
comm.send(vsota, dest=0, tag=1) - Zagotovite, da program deluje pravilno tudi če N ni natančno mnogokratnik procesov P.
- Namesto po blokih raje uporabite preskoke (stride oziroma step) v ukazu range()
- Uporabite redukcijo za delne vsote
#..
pi = comm.reduce(vsota, op=MPI.SUM, root=0)
if rank == 0:
print "Pi =", 4*pi/N - Potem ko ste izračunali vsoto Pi jo pošljite še vsem procesom z
pi = comm.bcast(vsota, root=0)
- Uporabite funkcijo MPI.Wtime() za merjenje stenčasa. Funkcijo je potrebno klicati na začetku in potem še na koncu izračunati razliko. S tem lahko tudi preverimo ali je koda pravilno balansirana po procesorjih. Na primer
t0 = MPI.Wtime()
#... računamo
print "preteklo =", MPI.Wtime() - t0 - Preverite ali v primeru da v zanki glavnega procesa sprejemate rezultate v poljubnem vrstnem redu tako, da rečete
deluje hitreje kot če zahtevate natančen vrstni red. Koliko procentov hitreje je wildcard sprejem? Poskusite ponoviti izračun večkrat, da dobite boljši povprečni rezultat. Kaj pa če naredimo dva dela kode, ki se hkrati izvajata in vsak računa svoj Pi. Ali lahko to potem ločimo v wildcard z izbiro tag-a?vsota += comm.recv(source=MPI.ANY_SOURCE, tag=1) - Primerjajte aproksimacijo z
import math
#..
error = pi - math.pi
Ping Pong
- Napiši program v katerem si dva prrocesa (rank 0 in rank 1) ponavljajoče izmenjujeta sporočila v obliki celoštevičnega polja sem in tja. Uporabite polja iz knjižnice NumPy. Program deluje tako pri tenisu
- rank 0 pošlje sporočilo na rank 1
- rank 1 sprejme to sporočilo in pošlje sprejeto sporočilo nazaj na rank 0
- rank 0 sprejme sporočilo od rank 1 in ga vrne
-
# -*- coding: utf-8 -*-
from mpi4py import MPI
import numpy
comm = MPI.COMM_WORLD
rank = MPI.COMM_WORLD.Get_rank()
size = MPI.COMM_WORLD.Get_size()
name = MPI.Get_processor_name()
if size != 2:
print("Uporabi mpirun -np 2 python pingpong.py")
exit(1)
# predalociramo polje
bufsize = 1*1024*1024
if rank == 0:
data = numpy.arange(bufsize, dtype='i')
elif rank == 1:
data = numpy.empty(bufsize, dtype='i')
loops = 1000
for x in range(loops):
if rank == 0:
comm.Send([data, MPI.INT], dest = 1, tag=0xdead)
comm.Recv([data, MPI.INT], source=1, tag=0xbeef)
else:
comm.Recv([data, MPI.INT], source=0, tag=0xdead)
comm.Send([data, MPI.INT], dest = 0, tag=0xbeef)
if rank == 0:
print "Pretočeno %d MB podatkov" % (2*bufsize*loops/1024/1024) Program popravite tako, da bo delaloval tudi če bo več procesorjev, kot je potrebno. V tem primeru naj ostali procesorji ne delajo nič.
Vstavite ukaze MPI.Wtime() za merjenje časa. Potrebno bo več ponovitev, še posebej pri manjših sporočilih, da boste dobili relevantne rezultate. Izdelajte tabelo v naslednji obliki:
Rezultati Ping Pinga velikost (byte) # iteracij Skupen čas (s) Čas na sporočilo Hitrost prenosa (MB/s) - Opazujte kako se čas preminja z velikostjo sporočila. Kaj je asimptotična hitrost prenosa?
- Izriši graf glede na velikost sporočila, da določite latenco (čas potreben za sporočilo nične velikosti).
- Napišite program v katerem glavni proces pošilja sporočilo vsem ostalim procesom v MPI.COMM_WORLD in nato sprejme sporočila nazaj. Kako se spreminja potreben čas sporočila glede na število procesov?
Preveri hitrost komunikacije na dveh vozliščih preko infinibanda (OPENIB) in etherneta (TCP) z ukazoma
bsub -n 2 -R "span[ptile=1]" -o pp-oib.txt mpirun --mca btl ^tcp python pingpong.py
bsub -n 2 -R "span[ptile=1]" -o pp-tcp.txt mpirun --mca btl ^openib python pingpong.py- Napišimo program, ki bo seštel globalno vsoto z uporabo posredovanja naključnih števil okoli obroča. Vsak proces mora poznati številko svojih sosedov v obroču.
from mpi4py import MPI
from random import randint
comm = MPI.COMM_WORLD
rank = MPI.COMM_WORLD.Get_rank()
size = MPI.COMM_WORLD.Get_size()
name = MPI.Get_processor_name()
counter = 0
data = randint(0,100)
for x in xrange(size):
comm.send(data, dest=(rank+1)%size, tag=7)
data = comm.recv(source=(rank+size-1)%size, tag=7)
counter += data
print("[%d] Skupna vsota: %d" % (rank,counter)) Če namesto naključnih števil inicializiramo lokalne vrednosti vseh P procesorjev na (rank+1)**2, ali dobite pravilen rezultat P(P+1)(2P+1)/6?
Izmerite čas potreben ya globalno vsoto in koliko je potrebno za obdelavo posameznega sporočila?
Uporabite sendrecv() ukaz namesto para send/recv.
NumPy v MPI4Py
NumPy in MPI4Py se uporabljata skupaj in sta učinkovita predvsem zaradi tega ker je ndarray kontunuirani blok podatkov, ki se lahko posreduje med procesi učinkovito v enem kosu in ne tako kot običajno, ko se v MPI4Py pošiljajo objekti, ki se morajo v procesih pakirati/razpakirati ob prenosu. Pomembna razlika pri pošiljanji/sprejemanju je v prvi črki ukaza, ki je z veliko začetnico (Send/Recv) in ne tako kot je običaj (send/recv). Druga pomemna značilnost NumPy prenosa je v sprejemu, saj mora biti polje v katerega sprejemamo že predalocirano.
Broadcast – Emitiranje ali razpošiljanje vsem se izvaja iz procesa 0.
# -*- coding: utf-8 -*-
import numpy as np
from mpi4py import MPI
comm = MPI.COMM_WORLD
if comm.rank == 0:
print "-"*78
print " Tečemo na %d jedrih" % comm.size
print "-"*78
comm.Barrier()
# Pripravimo vektor velikosti N=5 elements za razpošiljanje
N = 5
if comm.rank == 0:
A = np.arange(N, dtype=np.float64); # rank 0 ima vse podatke
else:
A = np.empty(N, dtype=np.float64); # vsi ostali pa le prazna polja
# Razpošljimo A iz procesa 0 vsem
comm.Bcast( [A, MPI.DOUBLE] )
# Vsi bi morali sedaj imeti enako polje...
print "[%02d] %s" % (comm.rank, A)
Scatter – razpršimo problem in ga razpečamo po obdelavi z Allgather
Razdelimo večji problem na manjši tako, da pošljemo podatke razdeljeno po koščkih, potem pa vsak pridobi rezultate še od ostalih in nadaljuje z delom s tem, da ima ponovno vse rezultate.
# -*- coding: utf-8 -*-
import numpy as np
from mpi4py import MPI
comm = MPI.COMM_WORLD
if comm.rank == 0:
print "-"*78
print " Tečemo na %d jedrih" % comm.size
print "-"*78
comm.Barrier()
my_N = 4
N = my_N * comm.size
if comm.rank == 0:
A = np.arange(N, dtype=np.float64)
else:
A = np.empty(N, dtype=np.float64)
my_A = np.empty(my_N, dtype=np.float64)
# Razdeli in pošlji (razpošlji) podatke data v my_A polja
comm.Scatter( [A, MPI.DOUBLE], [my_A, MPI.DOUBLE] )
if comm.rank == 0:
print("Po razpošiljanju:")
for r in xrange(comm.size):
if comm.rank == r:
print "[%d] %s" % (comm.rank, my_A)
comm.Barrier()
# Vsi sedaj množijo z 2
my_A *= 2
# Vsi poberejo od vseh (preostalo) nazaj v A
comm.Allgather( [my_A, MPI.DOUBLE], [A, MPI.DOUBLE] )
if comm.rank == 0:
print("Po sestavljanju:")
for r in xrange(comm.size):
if comm.rank == r:
print "[%d] %s" % (comm.rank, A)
comm.Barrier()
Razprševanje objektov
Razprševanje in sestavljanje je uporabno zaradi manjše komunikacije, saj velikokrat ni potrebno, da se vsi podatki razpošljejo vsem ampak le nujno potrebni.
# -*- coding: utf-8 -*-
# half mpirun -np 4 python ex4.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
if rank == 0:
data = [[1, 2], [3, 4], [5, 6], [7, 8]]
else:
data = None
print "Prvotni podatki za proces", rank, "so", data
razprseno = comm.scatter(data)
print "Proces", rank, "je sprejel", razprseno
pomnozeno = [i*2 for i in razprseno]
print "Proces", rank, "je pomnožil z 2 na", pomnozeno
pobrano = comm.gather(razprseno)
print "Pobrano oz oddano za proces", rank, "je", pobrano
Tag je oznaka sporočila
Pošiljanje in sprejemanje podatkov med dvema procesoma. tag je uporabniško določljiva oznaka sporočila.
# -*- coding: utf-8 -*-
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
data = [1, 2, 3]
comm.send(data, dest=1, tag=12)
print "Poslani podatki so: ", data
elif rank == 1:
data = comm.recv(source=0, tag=12)
print "Sprejeti podatki so: ", data
Redukcija
Z redukcijo izračunamo Pi
# -*- coding: utf-8 -*-
from mpi4py import MPI
import math
def compute_pi(n, start, step):
h = 1.0 / n
s = 0.0
for i in range(start, n, step):
x = h * (i + 0.5)
s += 4.0 / (1.0 + x**2)
return s * h
comm = MPI.COMM_WORLD
nprocs = comm.Get_size()
myrank = comm.Get_rank()
if myrank == 0:
n = 1000000
else:
n = None
n = comm.bcast(n, root=0)
mypi = compute_pi(n, myrank, nprocs)
pi = comm.reduce(mypi, op=MPI.SUM, root=0)
if myrank == 0:
error = abs(pi - math.pi)
print ("pi je približno %.16f, "
"napaka je %.16f" % (pi, error))
Mandelbrot
Mandelbrotov fraktal se ob zaključku shrani v datoteko, ki si jo ogledamo z ukazom
gimp mandelbrot.png
# -*- coding: utf-8 -*-
def mandelbrot(x, y, maxit):
c = x + y*1j
z = 0 + 0j
it = 0
while abs(z) < 2 and it < maxit:
z = z**2 + c
it += 1
return it
x1, x2 = -2.0, 1.0
y1, y2 = -1.0, 1.0
w, h = 6000, 4000
maxit = 127
from mpi4py import MPI
import numpy
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
# število vrstic, ki jih računamo v tem procesu
N = h // size + (h % size > rank)
# prva vrstica se začne na
start = comm.scan(N)-N
# polje za shranitev lokalnih rezultatov
Cl = numpy.zeros([N, w], dtype='i')
# preračunaj dodeljene vrstice
dx = (x2 - x1) / w
dy = (y2 - y1) / h
for i in range(N):
y = y1 + (i + start) * dy
for j in range(w):
x = x1 + j * dx
Cl[i, j] = mandelbrot(x, y, maxit)
# gather results at root (process 0)
counts = comm.gather(N, root=0)
C = None
if rank == 0:
C = numpy.zeros([h, w], dtype='i')
rowtype = MPI.INT.Create_contiguous(w)
rowtype.Commit()
comm.Gatherv(sendbuf=[Cl, MPI.INT],
recvbuf=[C, (counts, None), rowtype],
root=0)
rowtype.Free()
if comm.rank == 0:
from matplotlib import pyplot
pyplot.imshow(C, aspect='equal')
pyplot.spectral()
pyplot.savefig("mandelbrot.png")