- Predstavitev
- Uporaba
- Dostop
- Programski jeziki in knjižnice
- modules
- Nadzornik računskih virov SLURM
- TotalView
- VisIt
- IOzone test
- OpenFOAM
- ppgplasma
- Inkscape
- LaTeX in SVG
- Access
- Analiza, razčlenitev in razhroščevanje
- Ansys
- BIT1
- Cluster Management Utility
- DDT
- Eclipse
- Elmer
- Goldfire Innovator
- MPI
- Mathematica
- NX shadow
- OpenMP
- Platform Managment Console
- Pošta
- R
- Subversion
- UGS NX
- Projekti in dogodki
- Prijava
- Wiki
Main menu
Nahajate se tukaj
Razvoj programov
Načeloma je možno razvijati vzporedne programe na vseh platformah in pošiljati izvorno kodo za prevajanje in poganjanje tudi iz delovnih postaj uporabnikov. Običajno pa je, da se programe razvija v okolju, ki se ga tudi uporablja za izvajanje. Na HPCFS je za razvoj namenjeno nadzorno vozlišče, ki ponuja v svojem naboru že prednameščena grafična orodja za celovit razvoj aplikacij. Poleg prednameščenih orodij so nameščeni še programski paketi in knjižnice, ki jih uporabniki sami izbirajo glede na potrebe in zahtevane različice. Izbor paketov omogoča orodje module za naslednjimi osnovnimi ukazi:
- module avail – izpiše dostopno programsko opremo
- module load ime-modula – izbere modul in omogoči uporabo
- module display – prikaže nastavitve za modul
Osnova za razvoj vzporednih programov je poznavanje programskih jezikov in OpenMP ali MPI standarda. Za lažji razvoj so prednameščena tudi vizualna orodja za urejanje kode (eclipse, kate, gedit, emacs, ....) in razhoščevanje z TotalView, gdb, ddd, ... Za analizo rezultatov so primerna orodja kot je VisIt, ParaView, IDL, ...
Za učinkovito sledenje projektom so na voljo strežniki subversion, git, trac, gforge, …
Razvoj programov s prevajalniki in knjižnicami
Pri reševanju znanstvenih problemov se osredotočamo na
- učinkovite metode pri razvoju programa,
- uporabnost in vzdrževanje,
- Analizo in zapisovanje rezultatov,
- skrajševanje potrebnega časa za simulacije.
Za razvoj programov je potrebno dobro poznavanje prevajalnikov in knjižnic. Za vzporedno programiranje sta najbolj optimizirana prevajalnika za C++ in Fortran proizvajalca Intel, saj je sestav HPCFS poganjajo prav procesorji Intel. Poleg tega so zelo uporabni tudi odprtokodni prevajalniki GNU. Knjižnice so lahko statične (.a ali .llib) ter dinamične (.so ali .dll). Poleg prevajalnikov imamo na voljo še kopico orodij za delo z objektno kodo. Taka orodja so npr:
- nm: izpiše seznam objektov v prežvečeni objektni datoteki ali knjižnici
- dis: razdeljevalnik objektne kode (nasprotje as)
- ldd: izpiše seznam dinamičnih knjižni, ki jih program potrebuje
- file: izpiše osnovne informacije o datoteki
- strings: izlušči besede iz binarne datoteke
- od alj objdump: preuči poljubne binarne datoteke
Izbira programskega jezika je odvisna od znanja in primernosti za izbran cilj. Standardno se je za znanstvene probleme uporabljalo Fortran ali C. V novejšem času pa se za pomoč uporabljajo tudi novejši jeziki s katerimi analiziramo, interpretiramo, upravljamo in predstavljamo podatke. Običajno je že, da se programska koda nadzoruje tako, da za njo skrbi strežnik kot je subversion ali git in hkrati skrbi tudi za nadzor nad verzijami. Podobno velja tudi za konfiguracije simulacij.
Nameščeni prevajalniki
Poleg standardnih Gnu Compiler Collection so nameščena še Intel® Cluster Studio za Linux (poznan kot Intel® Cluster Toolkit Compiler Edition for Linux), ki vsebuje naslednje prevajalnike in knjižnice:
- Intel® Cluster Studio for Linux (formerly Intel® Cluster Toolkit Compiler Edition for Linux*)
- Intel® C++ Composer XE for Linux
- Intel® Fortran Composer XE for Linux
- Intel® Math Kernel Library for Linux
- Intel® MPI Library for Linux
- Intel® Trace Analyzer and Collector for Linux
Nameščena licenca omogoča hkratno prevajanje dveh uporabnikov (plavajoča licenca) na nadzornem vozlišču kot tudi na računskih vozliščih v interaktivnem načinu. Prevajalniki Intel so v primerjavi z ostalimi nekoliko boljšji pri optimiziranju kode za procesorje, ki so uporabljani na sestavu in se zato priporočajo za vse programe. Poleg najnovejših prevajalnikov so navoljo tudi starejše različice teh prevajalnikov, ki se izberejo z okoljem modules.
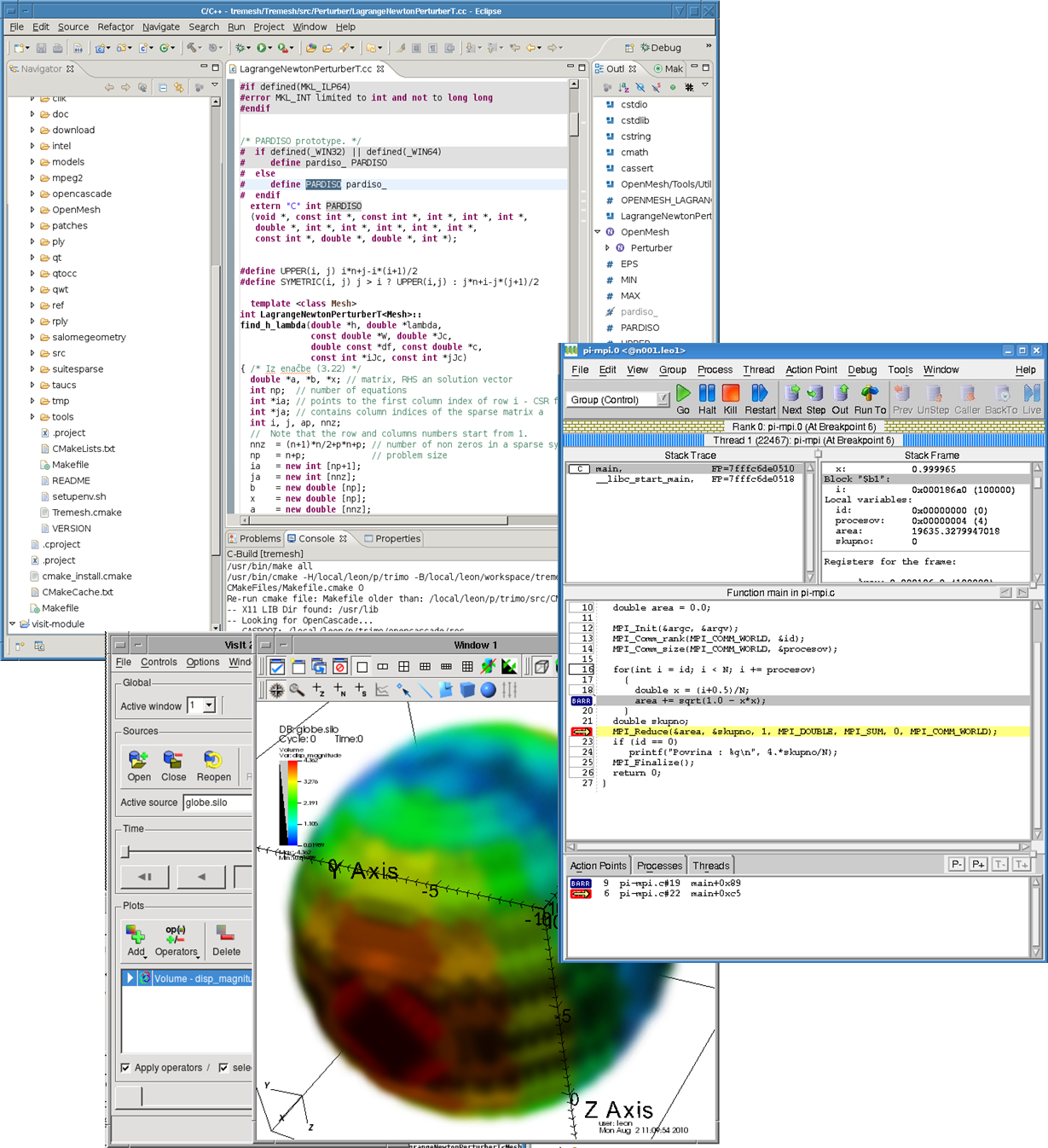
Vizualizacija podatkov
Za prostorsko vizualizacijo se največ uporabljajo programi
- VisIt - orodje z mhogo vhodnimi formati in možnostjo razširitev z vsadki za branje le teh
- Mayavi2 - temelji na Pythonu in omogoča skriptiranje
- Paraview - osnova za vizualizacijo v programu OpenFOAM
Visoko nivojske I/O knjižnice za zapis podatkov
Namen visokonivojskj I/O knjižnic je omogočanje razvijalcem višji novo abstrakcije pri manipilaciji z računskim objekti kar so lahko tudi nestruktuirane mreže. Obstoječe knjižnice, ki so uporabne so
- SILO - širok spekter objektov. Zapis temelji na formatu HDF5. SILO je naravni format za VisIt.
- EXODUS - Nestruktuirane mreže. Zapis temelji na NetCDF.
- eXtensible Data Model and Format (XDMF) - XML jezik
Format XDMF
Sestavljen je iz dveh delov:
- Enostavni podatki - XML podatki
- Zahtevni podatko - HDF datoteke
Prednost take kombinacije je, da lahko uporabimo obstoječe podatke z dodatko XML. Obstoječe I/O procedure ni potrebno popravljati. Dodati je le pisanje XML in že lahko beremo zahtevne kombinacije zapisov kost so domene, topologije, geometrije, mreže in podatki v XML.
- Prijavi se za komentar