- Predstavitev
- Uporaba
- Dostop
- Programski jeziki in knjižnice
- modules
- Nadzornik računskih virov SLURM
- TotalView
- VisIt
- IOzone test
- OpenFOAM
- ppgplasma
- Inkscape
- LaTeX in SVG
- Access
- Analiza, razčlenitev in razhroščevanje
- Ansys
- BIT1
- Cluster Management Utility
- DDT
- Eclipse
- Elmer
- Goldfire Innovator
- MPI
- Mathematica
- NX shadow
- OpenMP
- Platform Managment Console
- Pošta
- R
- Subversion
- UGS NX
- Projekti in dogodki
- Prijava
- Wiki
Main menu
Nahajate se tukaj
Message Passing Interface (MPI)
MPI je dominanten način komuniciranja s pošiljanjem sporočil. Sporočila se pošiljajo na nivoju procesov. Model MPI omogoča vzporedno izvajanje s sodelovanjem večih procesov na isti nalogi. Vsak proces ima pri delu svoje podatke. Procesi komunicirajo tako, da si med sabo pošiljajo in sprejemajo sporočila.Večina MPI programov temelji na modelu SPMD (Single-Program-Multiple-Data), kar pomeni, da vsi procesi izvajajo isti program s svojimi podatki. Da se omogoča medsebojno delo imajo procesi vsak svoj ID. Običajno se poganja en proces na eno procesorsko jedro.
Sporočila
Sporočilo prenaša številne podatke določenega tipa iz spomina v spomin drugega procesa. Sporočilo tipično vsebuje
- ID pošiljatelja in prejemnika
- tip podatkov
- količino podatkov
- podatke
- tip sporočila
Pošiljanje sporočil je možno sinhrono ali asinhrono. Sprejemi so običajno sinhroni, kar pomeni da mora sprejemni proces počakati, da se celotno sporočilo sprejme. Obstajajo tudi različni modeli komunikacije
- Point-to-Point - med dvema procesoma
- Collective - skupinska komunikacija med več procesi:
- Broadcast - Pošiljanje iz enega procesa na vse ostale
- Scatter - pošiljanje informacije več procesov
- Gather - prejemanje informacije večih procesov
- Reduction - gobalen seštevek, produkt, min, max, ...
Težave pri pisanju MPI so lahko zamrznitve (deadlock) oz čakanje na sporočila, ki nikoli ne pridejo. Večina znanstvenih programov ima enostavno zgradbo kar rezultira v enostavnem vzorcu komunikacij. Glavni namen programov MPI je prenosljivost kode in učinkovita implementacija vzporednega programa.
Programiranje
Za uporabo knjižnice MPI v programu je potrebno najprej vključiti v izvorno datoteko ustrezne glave za kontrolo tipov:
- C in C++: #include
- Fortran 77 (se ne priporoca vec): include ‘mpif.h'
- Fortran 90: use mpi
- Fortran 95 in MPI 3.0: use MPI_f08
Ukazi za klicanje knjižnice so naslednje oblike:
C:
error = MPI_Xxxxx(parameter, ...);
MPI_Xxxxx(parameter, ...);
Fortran:
CALL MPI_XXXXX(parameter, ..., IERROR)
Označbe (handles)
Z označevalni je mogoče naslavljati interne strukture MP. V C-ju so ozančevalci definirani tipi z typedef. V fortranu do to INTEGER-ji
Inicializacija
Pred začetkom dela, je potrebno inicializirati knjižnico MPI z ukazom
C:
int MPI_Init(int *argc, char ***argv)
Fortran:
MPI_INIT(IERROR)
INTEGER IERROR
Da dobimo ID ali rank oziroma številko procesa kličemo ukaz
MPI_Comm_rank(MPI_Comm comm, int *rank)
MPI_COMM_RANK(COMM, RANK, IERROR)
INTEGER COMM, RANK, IERROR
Celotno število procesov v inicializaciji dobimo z
MPI_Comm_size(MPI_Comm comm, int *size)
MPI_COMM_SIZE(COMM, SIZE, IERROR)
INTEGER COMM, SIZE, IERROR
Na koncu se program konča z
int MPI_Finalize()
MPI_FINALIZE(IERROR)
INTEGER IERROR
Sporočila
- Sporočilo vsebuje množico elementov določenega tipa
- Tipi MPI
- Osnovni tipi
- Izpeljani tipi
- Izpeljani tipi so lahko sestavljeni iz osnovnih
- Tipi v C-ju so različni od tipov v Fotranu
| MPI tip podatka | Tip v C-ju |
|---|---|
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | |
| MPI_PACKED |
| MPI tip podatka | Tip v Fortranu |
|---|---|
| MPI_INTEGER | INTEGER |
| MPI_REAL | REAL |
| MPI_DOUBLE_PRECISION | DOUBLE PRECISION |
| MPI_COMPLEX | COMPLEX |
| MPI_LOGICAL | LOGICAL |
| MPI_CHARACTER | CHARACTER(1) |
| MPI_BYTE | |
| MPI_PACKED |
Sporočila lahko pošiljamo na različne načine
- standardno
- sinhrono
- z vmesnim pomnilnikom (buffered)
- Sporočilo pripravljenosti
- sprejem
Primer pošiljanjja sinhronega sporočila je
int MPI_Ssend(void *buf, int count,
MPI_Datatype datatype,
int dest, int tag,
MPI_Comm comm)
ali v fortranu:
MPI_SSEND(BUF, COUNT, DATATYPE, DEST,TAG, COMM, IERROR)
BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG
INTEGER COMM, IERROR
Sprejemamo pa ga z:
int MPI_Recv(void *buf, int count,
MPI_Datatype datatype,
int source, int tag,
MPI_Comm comm, MPI_Status *status)
ali v Fortranu
MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR)
BUF(*)
INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM,
STATUS(MPI_STATUS_SIZE), IERROR
Za uspešno komuniciranje je vedno potrebno podati pravilen naslov končnega sprejemnika (rank). Tudi prejemnik mora podati vir iz katerega sprejem. Skladni morajo biti tui TAG-i, tip sporočila in seveda zadostna velikost rezerviranega spomina za sprejem.
Input/Output ali Vhod/Izhod
Običajno je pozabljena omejitev HPC prav vhod in izhod iz programov, saj celo standardni HP Linpack test ne upošteva I/O. Vendar pa morajo podatki na koncu obležati na zunanji enoti. Problem HPC sistemov je v simultanem dostopu do diskovnega podsistema kar vodi do zahtevne implementacije z več porazdeljenih RAID skupin, posrednikov do podatkov (MDS), vmesnih pomnilnikov, ... Več procesov ne more hkrati pisati v isto datoteko.
POSIX I/O je standarden način dosttopanja do datoetk na klasičnih računalnikih vendar nima podprtega vzporednega dostopa, ki ga HPC potrebuje. Posix način je možno uporabiti v glavnem MPI programu, ki skrbi za vse delo z datotekami. Vse to lahko poveča komunikacijo.
MPI I/O - Za naprednejše delo se uporabi MPI I/O knjižnice, ki so del MPI-2 standarda in temelji na poljih za katere skrbi knjižnica.
Delo y datotekami v MPI IO se začne z odpiranjem:
MPI_File_open(MPI_Comm comm, char *filename, int amode, MPI_Info info, MPI_File *fh)
MPI_FILE_OPEN(COMM, FILENAME, AMODE, INFO, FH, IERR)
CHARACTER*(*) FILENAME
INTEGER COMM, AMODE, INFO, FH, IERR
Primer:
MPI_File fh;
int amode = MPI_MODE_RDONLY;
MPI_File_open(MPI_COMM_WORLD, “data.in”, amode, MPI_INFO_NULL, &fh);
integer fh
integer amode = MPI_MODE_RDONLY
call MPI_FILE_OPEN(MPI_COMM_WORLD, ‘data.in’, amode, MPI_INFO_NULL, fh, ierr)
Zapremo jo z
MPI_File_close(MPI_File *fh)
MPI_FILE_CLOSE(FH, IERR)
INTEGER FH, IERR
Branje podatkov izbranega tipa na vsakem procesu je možno z
MPI_File_read_all(MPI_File fh, void *buf, int count,MPI_Datatype datatype, MPI_Status *status)
MPI_FILE_READ_ALL(FH, BUF, COUNT, DATATYPE, STATUS, IERR)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERR
Nastavimo lahko tudi poglede na datoteko in s tem določimo različne začetke za podatke v datoteki. S tem lako naredimo sestavljanko podatkov vseh procesov.
Izpeljani podatkovni tipi
MPI ima množico osnovnik tipov. Možno je pošiljati tudi dele polj. če npr. želimo poslati le del polja int[10] uporabimo ukaz
MPI_Send(x, 4, MPI_INT, ...);
Lahko izberemo tudi začetek s podajanjem kazalca
MPI_Send(&x[2], 4, MPI_INT, ...);
MPI_SEND(x(3), 4, MPI_INTEGER, ...)
Če želimo pošiljati le dele matrik oz vektorjev, lahko to naredimo z izpeljanim tipom.
MPI_Type_vector(int count, int blocklength, int stride, MPI_Datatype oldtype, MPI_Datatype *newtype);
MPI_TYPE_VECTOR(COUNT, BLOCKLENGTH, STRIDE,OLDTYPE, NEWTYPE, IERR)
INTEGER COUNT, BLOCKLENGTH, STRIDE, OLDTYPE
INTEGER NEWTYPE, IERR
MPI_Datatype vector3x2;
MPI_Type_vector(3, 2, 4, MPI_FLOAT, &vector3x2)
MPI_Type_commit(&vector3x2)
integer vector3x2
call MPI_TYPE_VECTOR(2, 3, 5, MPI_REAL, vector3x2, ierr)
call MPI_TYPE_COMMIT(vector3x2, ierr)
kar lahko uporabimo za pošiljanje
MPI_Send(&x[0][0], 1, subarray3x2, ...);
MPI_SEND(x , 1, subarray3x2, ...)
MPI_SEND(x(1,1) , 1, subarray3x2, ...)
Enostranska komunikacija
Pri modelu z enostansko komunikacijo sprejemnik ne sodeluje neposredno. Oddaljeni spomin se lahko naslovi tudi neposredno -- Remote Memory Access (RMA). Z RMA lahko dosegamo celoten spomin. Celo v ditribuiranih arhitekturah. V standardu MPI-2 imamo
- origin - proces ki izvede kloc
- target - proces v katerega spomin se posega
- source - polje iz katerega so podatki kopirani
- destination - polje v katerega so podatki skopirani
Enostransk komunikacija je glavnina pri vzpostavitvi standarda MPI-2. Dostop do RMA spomina je potrebno sinhronizirati, da ne prite do hkratnega pisanja in branja na istih lokacijah. To lahko dosežemo z
- kolektivno sinhronizacijo preko vseh procesorjev (z mejniki - MPI_Barrier),
- medsebojno sinhronizacijo
- zaklepi (locks)
Najbolj osnoven dostop do oddaljenega spomina je z
MPI_PUT(origin_addr, origin_count, origin_datatype, target_rank, target_disp,
target_count, target_datatype, window)
S klici RMA okna (windows) zamenjujejo komunikatorje. Ni pa možnosti načina prenosov in so vse operacije brez blokad. Tako se lahko zgodi, da program nadaljuje z delom še preden so bili podatki prenešeni. To pa zahteva tudi, da se medtem podatki pošiljatelja ne smejo popravljati. Do sinhronizacije z npr MPI_WIN_FENCE, zaklepi ali MPI_WIN_START/MPI_WIN_POST.
Optimizacija in deljeni komunikatorji v MPI
Izvajanje programov lahko upočasni naslednje kategorije:
- pomanjkanje vzporednosti - Amdahlov zakon Tp = Ts( (1-a)/p + a)
- slaba porazdelitev bremena
- sinhronizacija
- komunikacija
Namesto komunikatorja MPI_COMM_WORLD lahko uporabimo tudi manjše komunikatorje zato, da združimo procese glede na arhitekturno zgradbo komunikacij. Pri razdelitvi komunikatorja MPI_COMM_WORLD imajo potem procesi ranke štete po vrsti v vsakem komunikatorju posebej.
Primeri MPI programov
Hello, world
Izdelajmo MPI program, ki izpiše standardni pozdrav na Prelogu z uporabo LSF sistema. Program bo le izpisal pozdrav iz vsakega procesa. Za ugotovitev celotnega števila procesov uporabimo spremenljivko MPI_COMM_WORLD.
Za prevajanje moramo naprej izbrati okolje, kar naredimo z ukazom
module load intel openmpi
Program prevedemo z:
mpicc -g -o hello hello.c -limf -lm
Ustvarimo "batch" datoteko mpibatch.lsf z naslednjo vsebino:
#!/bin/sh
#BSUB -a openmpi
#BSUB -q normal
#BSUB -n 8
#BSUB -o hello-%J.out
#BSUB -e hello-%J.err
mpirun hello
in jo poženomo z ukazom bsub < mpibatch.lsf, ki v izhodno datoteko napiše rezultat in statistiko. Izpis programa je naslednji:
Pozdrav iz procesa št. 0
Skupno število procesov je 8
Pozdrav iz procesa št. 1
Pozdrav iz procesa št. 3
Pozdrav iz procesa št. 5
Pozdrav iz procesa št. 2
Pozdrav iz procesa št. 4
Pozdrav iz procesa št. 6
Pozdrav iz procesa št. 7
Izračun števila Pi
Želimo izračunati aproksimacijo števila pi z enačbo
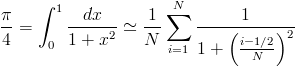
- Za osnovo uporabimo program hello.c tako, da vsak proces neodvisno izračuna vrednost pi. Preverimo ali vsi procesi izpišejo isto številko.
#include
#define N 840
#define SQR(x) (x)*(x)
int main(int argc, char *argv[])
{
int rank, velikost;
int i;
double pi = 0.0;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &velikost);
for (i=1; i < N; ++i)
pi += 1.0/(1.0+SQR((i-0.5)/N));
pi *= 4.0/N;
printf("Rezultat #%d: Pi= %lf\n", rank, pi);
if (rank == 0)
printf("Skupno število procesov je %d\n", velikost);
MPI_Finalize();
}
- Sedaj razdelimo procese tako, da računajo v različnih obsegih. Če bi imeli dva procesa bo rank 0 bo računal i=1..N/2, rank 1 pa i=N/2..N. N nastavimo na 840, saj je deljivo z 2 do 8. Izpišimo delne vsote in jih izračunamo na pamet.
#include
#define N 840
#define SQR(x) (x)*(x)
int main(int argc, char *argv[])
{
int rank, np;
int i, start, end;
float pi = 0.0;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &np);
start = N*rank/np+1; end = start + N/np-1;
printf("Obseg #%d : [%d:%d]\n", rank, start, end);
for (i=start; i <= end; ++i)
pi += 1.0/(1.0+SQR((i-0.5)/N));
pi *= 4.0/N;
printf("Delna vsota #%d: Pi= %f\n", rank, pi);
MPI_Finalize();
}
- Sedaj sestavimo delne vsote s pošiljanjem glavnemu procesu (rank 0) za seštevanje
- Vsi procesi (razen glavnega) pošiljajo delne vsote glavnemu
- glavni sprejema vrednosti vseh ostalih procesov in jih sešteje
- Za komunikacijo uporabimo MPI_Ssend() in MPI_Recv()
- Program dopolnnimo z
- Uporabimo funkcijo MPI_Wtime za izračun potrebnega časa za izračun
double starttime, endtime;
starttime = MPI_Wtime();
... računamo
endtime = MPI_Wtime();
printf("Pi = %f izračunan v %lf\n", pi, endtime-starttime);
- Preverimo in zagotovimo, da program deluje pravilno tudi če N ni mnogokratnik števila procesov P
Ping pong
Napišimo program. ki v dveh procesih (rank 0 in 1) ponavljajoče pošilja sporočila sem in tja. Uporabimo MPI_Send za posiljanje. Izdelati je potrebno program tako, da pravilno deluje tudi pri večjem številu procesov. Da poenostavimo bomo uporabili polje realnih števil ne da bi ga inicializirali.
- Dodajmo meritev časa za vse komunikacije
- Poglejmo kako čas varira z velikostjo sporočila
- Narišimo graf, da ugotovimo latenco (čas potreben za sporočilo velikosti nič).
program pingpong
use MPI_f08
implicit none
integer i, rank
integer buf_size
parameter (buf_size=8*64)
real buf(buf_size)
type(MPI_Status) :: stat
double precision :: start, finish
call MPI_Init()
call MPI_Comm_Rank(MPI_COMM_WORLD, rank)
do i=1,51
if (rank .eq. 0) then
if (i .eq. 2) start = MPI_Wtime()
call MPI_Send(buf, count=buf_size, datatype=MPI_REAL, dest=1, tag=17, comm=MPI_COMM_WORLD)
call MPI_Recv(buf, count=buf_size, datatype=MPI_REAL, source=1, tag=23, comm=MPI_COMM_WORLD, status=stat)
else if (rank .eq. 1) then
call MPI_Recv(buf, count=buf_size, datatype=MPI_REAL, source=0, tag=17, comm=MPI_COMM_WORLD, status=stat)
call MPI_Send(buf, count=buf_size, datatype=MPI_REAL, dest=0, tag=23, comm=MPI_COMM_WORLD)
end if
end do
finish = MPI_Wtime()
if (rank .eq. 0) then
print *, 'delta_time =', (finish-start)/(2*50)*1e6
end if
call MPI_Barrier(MPI_COMM_WORLD)
call MPI_Finalize()
end program
Enostranska komunikacija
Program za krozno vsoto predelamo v RMA nacin
#include <stdio.h>
#include <mpi.h>
#define to_right 201
int main (int argc, char *argv[])
{
int my_rank, size;
int snd_buf, rcv_buf;
int right, left;
int sum, i;
MPI_Win win;
MPI_Status status;
MPI_Request request;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
right = (my_rank+1) % size;
left = (my_rank-1+size) % size;
/* ... this SPMD-style neighbor computation with modulo has the same meaning as: */
/* right = my_rank + 1; */
/* if (right == size) right = 0; */
/* left = my_rank - 1; */
/* if (left == -1) left = size-1;*/
sum = 0;
snd_buf = my_rank;
MPI_Win_create(&rcv_buf, sizeof(int), sizeof(int), MPI_INFO_NULL,
MPI_COMM_WORLD, &win);
for( i = 0; i < size; i++)
{
#if 0
MPI_Issend(&snd_buf, 1, MPI_INT, right, to_right,
MPI_COMM_WORLD, &request);
MPI_Recv(&rcv_buf, 1, MPI_INT, left, to_right,
MPI_COMM_WORLD, &status);
MPI_Wait(&request, &status);
#else
MPI_Win_fence(MPI_MODE_NOSTORE | MPI_MODE_NOPRECEDE, win);
MPI_Put(&snd_buf, 1, MPI_INT, right, (MPI_Aint)0, 1, MPI_INT, win);
MPI_Win_fence(MPI_MODE_NOSTORE | MPI_MODE_NOPUT | MPI_MODE_NOSUCCEED, win);
#endif
snd_buf = rcv_buf;
sum += rcv_buf;
}
printf ("PE%i:\tSum = %i\n", my_rank, sum);
MPI_Finalize();
}
</mpi.h></stdio.h>
- Prijavi se za komentar