- Predstavitev
- Uporaba
- Dostop
- Programski jeziki in knjižnice
- modules
- Nadzornik računskih virov SLURM
- TotalView
- VisIt
- IOzone test
- OpenFOAM
- ppgplasma
- Inkscape
- LaTeX in SVG
- Access
- Analiza, razčlenitev in razhroščevanje
- Ansys
- BIT1
- Cluster Management Utility
- DDT
- Eclipse
- Elmer
- Goldfire Innovator
- MPI
- Mathematica
- NX shadow
- OpenMP
- Platform Managment Console
- Pošta
- R
- Subversion
- UGS NX
- Projekti in dogodki
- Prijava
- Wiki
Main menu
Nahajate se tukaj
HPL benchmark
HPL (High Performance LINPACK) je standardni industrijski test za HPC, ki rešuje (naključni) gosti linearni sistem v dvojni ločljivosti (64 bitov) na računalnikih s porazdeljenim spominom.
HPL test je primeren za testiranje sestavov predvsem zaradi tega, ker se pri testiranju upošteva procesorska moč, celotna količina spomina in povezava med vozlišči. Vhodna parametri programa niso vnaprej predpisani in se jih lahko prireja tako, da bo dobimo čim boljši rezultat, ki je izpisan kot GFlops. Za ocenjevanje pričakovanih rezultatov lahko uporabimo http://hpl-calculator.sourceforge.net/
Primer testa na sestavu z AMD Opteron procesorji 875 in 275, vsa vozlišča imajo 2GB RAM/jedro. Povezava med vozlišči je Ethernet 1Gb bond. HPL test je izveden na 64 procesorjih. Naslednja slika kaže potek testa pri 32 in 64 procesorjih. Videti je, da večje število procesorjev prispeva k večji zmogljivosti. Prav tako pa večja količina spomina oz večji problemi N dajejo boljše rezultate. Vse med seboj omejuje še komunikacija, zato pri večanju problema rezultati izzvenijo. Ko se bližamo mejni vrednosti razpoložljivega spomina se čas reševanja problema enormno poveča, kar pomeni da je začel sistem delovati v ostranjevanju (swapping).
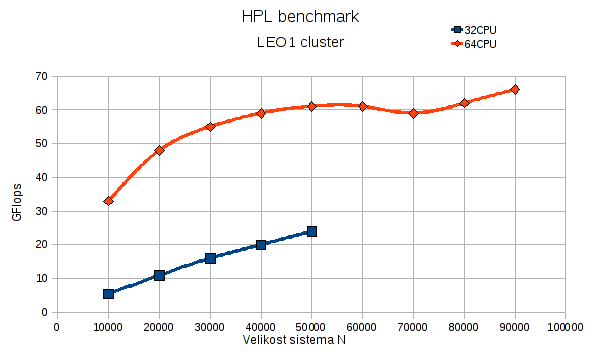
Datoteke
Vhodna datoteka HPL.dat ima naslednjo obliko:
HPLinpack benchmark input file Innovative Computing Laboratory, University of Tennessee HPL-64b.out output file name (if any) 0 device out (6=stdout,7=stderr,file) 8 # of problems sizes (N) 60000 70000 80000 90000 100000 110000 120000 130000 Ns 1 # of NBs 168 NBs 0 PMAP process mapping (0=Row-,1=Column-major) 1 # of process grids (P x Q) 4 Ps 5 Qs 16.0 threshold 1 # of panel fact 2 PFACTs (0=left, 1=Crout, 2=Right) 1 # of recursive stopping criterium 4 NBMINs (>= 1) 1 # of panels in recursion 2 NDIVs 1 # of recursive panel fact. 1 RFACTs (0=left, 1=Crout, 2=Right) 1 # of broadcast 1 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) 1 # of lookahead depth 0 DEPTHs (>=0) 2 SWAP (0=bin-exch,1=long,2=mix) 64 swapping threshold 0 L1 in (0=transposed,1=no-transposed) form 0 U in (0=transposed,1=no-transposed) form 1 Equilibration (0=no,1=yes) 8 memory alignment in double (> 0)
Izpis razporeditve po vozliščih:
c705185@login.leo1 hpl]$ qsub -N hpl64b benchmark.job
Your job 14500 ("hpl64b") has been submitted
[c705185@login.leo1 hpl]$ qstat -f|grep hpl
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 5
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 5
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 5
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 5
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 5
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 5
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
14500 0.00000 hpl64b c705185 r 02/07/2010 21:15:52 2
Izhodna datoteka HPL.out
================================================================================
HPLinpack 2.0 -- High-Performance Linpack benchmark -- September 10, 2008
Written by A. Petitet and R. Clint Whaley, Innovative Computing Laboratory, UTK
Modified by Piotr Luszczek, Innovative Computing Laboratory, UTK
Modified by Julien Langou, University of Colorado Denver
================================================================================
An explanation of the input/output parameters follows:
T/V : Wall time / encoded variant.
N : The order of the coefficient matrix A.
NB : The partitioning blocking factor.
P : The number of process rows.
Q : The number of process columns.
Time : Time in seconds to solve the linear system.
Gflops : Rate of execution for solving the linear system.
The following parameter values will be used:
N : 10000 20000 30000 40000 50000
NB : 168
PMAP : Row-major process mapping
P : 4
Q : 5
PFACT : Right
NBMIN : 4
NDIV : 2
RFACT : Crout
BCAST : 1ringM
DEPTH : 0
SWAP : Mix (threshold = 64)
L1 : transposed form
U : transposed form
EQUIL : yes
ALIGN : 8 double precision words
--------------------------------------------------------------------------------
- The matrix A is randomly generated for each test.
- The following scaled residual check will be computed:
||Ax-b||_oo / ( eps * ( || x ||_oo * || A ||_oo + || b ||_oo ) * N )
- The relative machine precision (eps) is taken to be 1.110223e-16
- Computational tests pass if scaled residuals are less than 16.0
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR01C2R4 10000 168 4 5 20.05 3.326e+01
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0035740 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR01C2R4 20000 168 4 5 111.98 4.763e+01
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0029062 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR01C2R4 30000 168 4 5 327.53 5.496e+01
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0033036 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR01C2R4 40000 168 4 5 723.10 5.901e+01
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0030808 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR01C2R4 50000 168 4 5 1357.67 6.138e+01
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0035634 ...... PASSED
================================================================================
Finished 5 tests with the following results:
5 tests completed and passed residual checks,
0 tests completed and failed residual checks,
0 tests skipped because of illegal input values.
--------------------------------------------------------------------------------
End of Tests.
================================================================================
SGE benchmark.job
#!/bin/bash # Parallel jobs must be placed into the queue 'par.q'. #$ -q par.q # The batch system should use the current directory as working directory. #$ -cwd # Redirect output stream to this file. #$ -o output.dat # Join the error stream to the output stream. #$ -j yes # Use the parallel environment "openmpi-fillup", which assigns as many processes # as available on each host. If there are not enough machines to run the MPI job # on the maximum of 16 cores, the batch system will gradually try to run the job # on fewer cores, but not less than 8. #$ -pe openmpi-4perhost 32 # #$ -l h_vmem=4G mpirun -np $NSLOTS bin/em64t/xhpl
Test enega samega vozlišča z X5530 in 12MB RAM
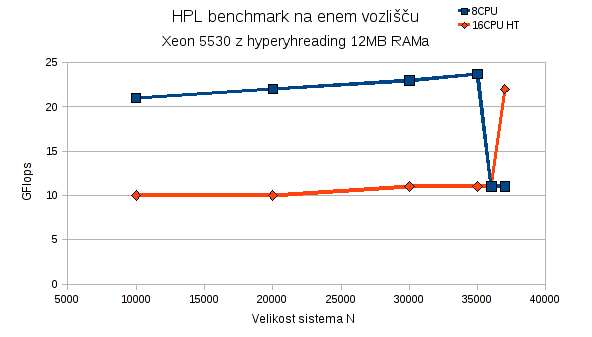
Pričakovana maksmalna velikost sistema za 12GB pomnilnika je okoli N=36000 kar se je tudi izkazalo na testu. Zanimivo je še, da hyperthreading na večjemu številu procesorjev pri tem testu precej škodi.
Test Opteron 6172 clustra
HPC Advisory council je odstopil v testiranje cluster s šestimi vozlišči AMD Opteron(tm) Processor 6172 in 32GB RAM-a/vozlišče. Prvo vozlišče je bilo uporabno le za prevajanje. Pet vozlišč ima skupaj 5*24=120 procesorskih jeder.
AMD 6000 Series platform, 8-node cluster (24-cores per node)
- AMD Opteron™ Model 6172, 45nm technology
- Mellanox ConnectX®-2 40Gb/s InfiniBand Adapters
- Mellanox M3601Q 36-Port 40Gb/InfiniBand Switch
- Memory: 32GB memory per node
[test03@g34003 ~]$ cpuinfo AMD Opteron(tm) Processor 6172 (Intel64) ===== Processor composition ===== Processors(CPUs) : 24 Packages(sockets) : 2 Cores per package : 12 Threads per core : 1 ===== Processor identification ===== Processor Thread Id. Core Id. Package Id. 0 0 0 0 1 0 1 0 2 0 2 0 3 0 3 0 4 0 4 0 5 0 5 0 6 0 6 0 7 0 7 0 8 0 8 0 9 0 9 0 10 0 10 0 11 0 11 0 12 0 0 1 13 0 1 1 14 0 2 1 15 0 3 1 16 0 4 1 17 0 5 1 18 0 6 1 19 0 7 1 20 0 8 1 21 0 9 1 22 0 10 1 23 0 11 1 ===== Placement on packages ===== Package Id. Core Id. Processors 0 0,1,2,3,4,5,6,7,8,9,10,11 0,1,2,3,4,5,6,7,8,9,10,11 1 0,1,2,3,4,5,6,7,8,9,10,11 12,13,14,15,16,17,18,19,20,21,22,23
[test03@g34001 ThirdParty-1.6]$ numactl --show policy: default preferred node: current physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 cpubind: 0 1 2 3 nodebind: 0 1 2 3 membind: 0 1 2 3
Ker sestav nima nikakršnega sistema čakalnih vrst je bil izbran Intel impi sistem in icc prevajalnik. Za nastavitev sistema štirih vozlišč z je potrebno pognati MPD procese in nato razdeliti z mpiexec. Seznam imen ali IP-jev vseh vozlišč od katerih izberemo štiri je v datoteki mpd.hosts. Daemone MPD lahko zaustavimo z mpdallexit.
[test03@g34003 em64t]$ mpdboot -f mpd.hosts -n 4 -r ssh [test03@g34003 em64t]$ mpiexec -np 64 ./xhpl
Seznam procesov se dobi z ukazom mpdlistjobs.
[test03@g34003 em64t]$ mpdlistjobs|grep host|uniq -c
24 host = g34003
24 host = g34006
16 host = g34004
Rezultati testa na 64 jedrih so delovali brez ostranjevanja do velikosti 60000.
================================================================================ T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR01C2R4 10000 168 4 5 6.96 9.581e+01 -------------------------------------------------------------------------------- WR01C2R4 20000 168 4 5 45.53 1.171e+02 -------------------------------------------------------------------------------- WR01C2R4 30000 168 4 5 144.69 1.244e+02 -------------------------------------------------------------------------------- WR01C2R4 40000 168 4 5 332.01 1.285e+02 -------------------------------------------------------------------------------- WR01C2R4 50000 168 4 5 637.09 1.308e+02 -------------------------------------------------------------------------------- WR01C2R4 60000 168 4 5 1095.77 1.314e+02
HPL na štirih vozliščih s 96 jedrih je ravno tako omejen z N=60000
T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR01C2R4 10000 168 4 5 7.08 9.417e+01 -------------------------------------------------------------------------------- WR01C2R4 20000 168 4 5 45.71 1.167e+02 -------------------------------------------------------------------------------- WR01C2R4 30000 168 4 5 144.28 1.248e+02 -------------------------------------------------------------------------------- WR01C2R4 40000 168 4 5 331.33 1.288e+02 -------------------------------------------------------------------------------- WR01C2R4 50000 168 4 5 635.56 1.311e+02 -------------------------------------------------------------------------------- WR01C2R4 60000 168 4 5 1094.95 1.315e+02
JSC HPC-FF cluster
S procesorji Intel X5570 in 24GB RAM/vozlišče. Test na 8 vozliščih z 8 jedri.
T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR01C2R4 10000 168 4 5 5.42 1.231e+02 -------------------------------------------------------------------------------- WR01C2R4 20000 168 4 5 29.00 1.839e+02 -------------------------------------------------------------------------------- WR01C2R4 50000 168 4 5 399.33 2.087e+02 -------------------------------------------------------------------------------- WR01C2R4 60000 168 4 5 683.01 2.108e+02 -------------------------------------------------------------------------------- WR01C2R4 70000 168 4 5 1074.11 2.129e+02 -------------------------------------------------------------------------------- WR01C2R4 80000 168 4 5 1602.99 2.129e+02
Za standardne velikosti sistemov se lahko uporabi naslednjo datoteko HPL.dat
PLinpack benchmark input file Innovative Computing Laboratory, University of Tennessee HPL.out output file name (if any) file device out (6=stdout,7=stderr,file) 1 # of problems sizes (N) 13920 Ns 1 # of NBs 232 NBs 0 PMAP process mapping (0=Row-,1=Column-major) 1 # of process grids (P x Q) 2 Ps 2 Qs 16.0 threshold 1 # of panel fact 1 PFACTs (0=left, 1=Crout, 2=Right) 1 # of recursive stopping criterium 4 NBMINs (>= 1) 1 # of panels in recursion 2 NDIVs 1 # of recursive panel fact. 1 RFACTs (0=left, 1=Crout, 2=Right) 1 # of broadcast 3 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) 1 # of lookahead depth 0 DEPTHs (>=0) 2 SWAP (0=bin-exch,1=long,2=mix) 232 swapping threshold 0 L1 in (0=transposed,1=no-transposed) form 0 U in (0=transposed,1=no-transposed) form 1 Equilibration (0=no,1=yes) 8 memory alignment in double (> 0)
Veliki sistemi
HPLinpack benchmark input file Innovative Computing Laboratory, University of Tennessee HPL.out output file name (if any) 8 device out (6=stdout,7=stderr,file) 1 # of problems sizes (N) 1475840 Ns 1 # of NBs 232 NBs 0 PMAP process mapping (0=Row-,1=Column-major) 1 # of process grids (P x Q) 32 Ps 317 Qs 16.0 threshold 1 # of panel fact 1 PFACTs (0=left, 1=Crout, 2=Right) 1 # of recursive stopping criterium 4 NBMINs (>= 1) 1 # of panels in recursion 2 NDIVs 1 # of recursive panel fact. 1 RFACTs (0=left, 1=Crout, 2=Right) 1 # of broadcast 3 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) 1 # of lookahead depth 1 DEPTHs (>=0) 2 SWAP (0=bin-exch,1=long,2=mix) 128 swapping threshold 0 L1 in (0=transposed,1=no-transposed) form 0 U in (0=transposed,1=no-transposed) form 1 Equilibration (0=no,1=yes) 8 memory alignment in double (> 0) ##### This line (no. 32) is ignored (it serves as a separator). ###### 0 Number of additional problem sizes for PTRANS 1200 10000 30000 values of N 0 number of additional blocking sizes for PTRANS 40 9 8 13 13 20 16 32 64 values of NB
| Priponka | Velikost |
|---|---|
| 12.95 KB | |
| 28.19 KB | |
| 13.99 KB | |
| 36.64 KB | |
| 52.68 KB |
{kind=link}
{kind=link}
- Prijavi se za komentar